1、一年前发布的 GLUE 是用于评估这些方案的一套基准和工具包 。GLUE 是九种(英语)语言理解任务的集合 , 包括文本蕴涵、情感分析和语法判断等 。其设计目的是覆盖足够大的 NLP 领域 , 以使得只有开发出足够通用的工具 , 才能在这一基准上表现良好;这样也有助于解决未来可能新遇到的语言理解问题 。
2、随着 GPT 和 BERT 的出现 , 模型水平大幅提升;而且随着研究者持续开发更好的算法以将 BERT 用于其它任务 , 模型的表现正在稳步追赶人类水平 。在三个 GLUE 任务(QNLI、 MRPC 和 QQP)上 , 最佳的模型已经超过了人类基准 , 但这并不意味着机器已掌握英语 。比如 , WNLI 任务涉及到确定一个句子「John couldn』t fit the trophy in the suitcase because it was too big.(约翰没法把奖杯放进箱子 , 因为它太大了 。)」究竟是指「奖杯太大」还是「箱子太大」 。人类可以完美地解决这一任务 , 而机器的表现还和随机乱猜差不多 。
3、SuperGLUE 与 GLUE 类似 , 是一个用于评估通用 NLP 模型的基准 , 同样也基于在多种不同语言理解任务集上的评估 。
为了发现新的挑战性任务集 , SuperGLUE 提出者向更广泛的 NLP 社区发起了任务提议征集 , 得到了一个包含约 30 种不同 NLP 任务的列表 。在选择 SuperGLUE 的任务时 , 提出者考虑了多项设计原则 , 包括必须涉及到语言理解、这些任务还无法通过已有的方法解决、存在公开的训练数据、任务格式以及证书 。经过验证 , 最终得到了一个包含七个任务的集合 。
4、SuperGLUE 遵照了 GLUE 的基本设计:包含一个围绕这七个语言理解任务构建的公开排行榜、基于已有数据的抽取、一个单个数值的表现指标和一套分析工具包 。
SuperGLUE 与 GLUE 也有很多差异:
- SuperGLUE 仅保留了 GLUE 九项任务中的两项(其中一项还经过修改) , 还引入了五个难度更大的新任务 。这些任务的选择标准包括为了实现难度和多样性的最大化 。
初始的 SuperGLUE 基准版本即包含了人类水平估计结果 。在 SuperGLUE 中这些被选中的任务上 , 基于 BERT 的强基线与人类水平之间还存在显著的差距 。
任务格式(API)的集合在 GLUE 中的句子和句子对分类上进行了扩展 , SuperGLUE 另外还包含共指消解、句子完成和问答 。
为了促使研究者针对这种多样性的任务集合开发统一的新方法 , 与 SuperGLUE 一起发布的还有一套用于操作 NLP 的预训练、多任务学习和迁移学习的模块化建模工具包 。这套工具包基于 PyTorch 和 AllenNLP 。
管理 SuperGLUE 排行榜的规则有多个地方不同于 GLUE 排行榜的管理规则 , 这些变化都是为了确保该排行榜竞争公平、信息丰富 , 并能充分体现数据和任务创建者的贡献 。
SuperGLUE 与 GLUE 的两项共同任务是:识别文本蕴涵(RTE)和 Winograd 模式挑战赛(WSC) 。此外 , SuperGLUE 还添加了测试模型问答、执行共指消解和执行常识推理能力的任务 。
5、SuperGLUE 基准也设置了一个总体评估指标:SuperGLUE 分数 。该分数即是在以上所有任务上所得分数的平均 。对于 Commitment Bank 和 MultiRC , 会首先先取该任务在各项指标上的平均 , 比如对于 MultiRC , 会首先先平均 F1m 和 F1a , 之后在整体平均时将所得结果作为单个数值纳入计算 。另外 , GAP 的偏见(bias)分数不会纳入 SuperGLUE 分数的计算;原因是在性别平衡的 GAP 上训练的大多数系统在偏见分数上都表现良好 。
6、为了进一步挑战AI系统 , SuperGLUE还首次引入了长篇问题回答数据集和基准测试 , 这需要AI能提供长而复杂的答案 , 这是此前没有遇到过的挑战 , 有助于发现了当今最先进的NLU系统的一些局限性 。
7、目前的问答系统专注于琐事类型(trivia-type)的问题 , 例如“水母是否有大脑” 。新的任务将更进一步要求系统对开放式问题的深入解答进行详细的阐述 , 需要系统能够回答“水母如何在没有大脑的情况下运作?”
现有算法与人类的水平还相差很远 , 这一新挑战将推动AI合成来自不同来源的信息 , 并提供开放式问题的复杂回复 。
【新推出的AI语音理解基准测试SuperGLUE,较GLUE有多大的提升】除了新的测试基准外 , 纽约大学还同时发布了相关的PyTorch语言理解工具包Jiant 。
秒懂知识为您整理更多相关内容。
SuperGLUE(Super General Language Understanding Evaluation)是当下NLP领域难度最大 , 权威性最高 , 含金量最足的测评标准之一 , 由纽约大学、华盛顿大学以及谷歌旗下的DeepMind联合Facebook作为主要发起人推出 , 最大程度涵盖了现实生活中可能遇到的不同类型的NLP任务 , 旨在更真实地反映当前最前沿的NLP技术可以达到的认知智能水平 。
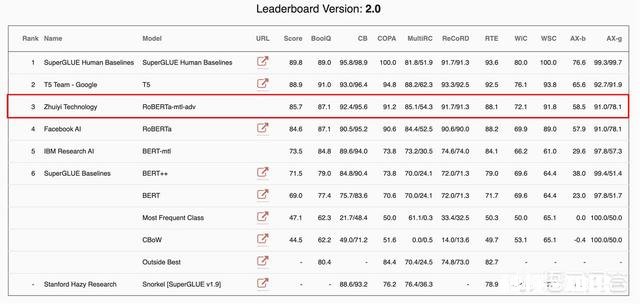
近日 , 自然语言处理领域权威数据集SuperGLUE最新榜单排名更新 。Google预训练模型T5保持第一 , 中国AI创业公司追一科技AILab团队超越Facebook AI , 跃居榜单第二 。值得注意的是 , 相比谷歌T5等超大规模研究型模型 , 追一此次登榜的RoBERTa-mtl-adv模型在商业化能力也非常强劲 , 相关技术已经落地到追一科技的AI数字员工产品线上 , 持续赋能银行、保险、证券、零售、地产、能源 , 教育 , 互联网等多个行业 。
文章插图
追一科技跃居SuperGLUE测试榜第二
除去作为参照的人类水平 , 目前排名榜单第一的是Google的T5模型 。从学术研究看 , T5模型达到了目前“实验室智能”的最好水平 , 但如果考虑商用 , T5需要耗费大量的算力 , 且模型自身体积过于庞大 , 目前还不能落地到实际业务场景中 , 缺少实际的商业应用价值 。
而追一科技通过多任务学习、对抗训练以及知识蒸馏的方式 , 使得RoBERTa-mtl-adv模型大小合理 , 效果仅次于Google的T5 。同时 , 相关技术也落地到了追一科技AI数字员工的产品线上 。就SuperGLUE排名而言 , 可以说追一科技的RoBERTa-mtl-adv模型在目前全球具有实际落地能力的NLP模型中效果最好 , 排名最高 。
从GLUE到SuperGLUE:难度更大
SuperGLUE在GLUE设计的基础上 , 采用了一系列更加困难的语言理解任务 , 除了共同任务识别文本蕴涵(RTE)和 Winograd 模式挑战赛(WSC)外 , 还添加了常识推理和词义消除等任务 , 上表中给出的其他测试数据集包括:
CB短文本语料库
MultiRC真假问答任务数据集
COPA因果推理
WiC词义消岐
RoBERTa离人类还有多远
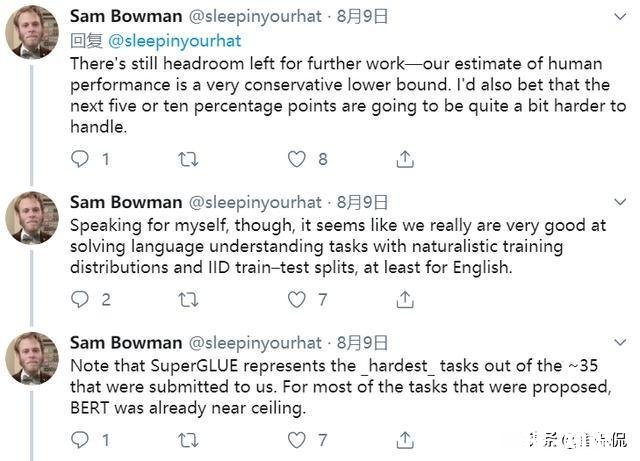
从SuperGLUE排行榜上看 , RoBERTa的得分距离人类只有5.2分 , 但是NYU数据科学中心助理教授Sam Bowman在其推特上 , 关于这一排行榜RoBERTa直逼人类的表现也发表了看法 。
文章插图
RoBERTa在SuperGLUE得分逼近人类 , 甩baseline十多个点
SuperGLUE代表的是我们需要处理的35个任务中最难的几个 。而对于35个中的大多任务 , BERT 本身的性能就已经快接近极限了 。
还有几点需要注意:
RoBERTa良好的表现很大程度受益于充足的数据集:ReCoRD和MultiRC 。效果转移到数据不佳的任务比较困难 。
WinoGender coref.accuracy表现较好 , 但代价是gender parity更差 。
RTE模型在downward monotone inferences仍然表现较差:例如 , 它倾向于假设“所有的狗都喜欢抓它们的耳朵” 。“所有动物都喜欢搔耳朵 。”
Sam Bowman认为 , 他对觉得RoBERTa有个明显的天花板 , 而我们对于人类表现有一个比较低的估计 , 他敢打赌 , 接下来的5到10个百分点将变得相当难以突破 。
让我们期待通过算力数据以及大模型(Transformer) , 人类到底能够将NLP推到什么程度吧!
- 伦敦发生爆炸,难道是恐袭来临
- 刺客信条大革命伊甸剑和苏杰之鹰哪个伤害高,指单纯的单击伤害,不算上苏杰的闪光
- 孩子要上初中了,英语成绩不是太好,听他们说阿尔法蛋不错,应该买大蛋还是小蛋
- 早晨落地第一脚疼痛难忍,医生查出跟骨骨刺,患者将来还能走路吗
- 人一生可以做几次股骨关节置换
- 不粘锅可以做蛋糕吗怎么做
- 陕北有哪些好吃的
- 癌症与痛风患者在饮食上需要注意什么